Amazon Elastic MapReduce (EMR) : Menjalankan Apache Spark mode Fully Distributed dengan Biaya kurang dari Rp 1.500,-
Men-setup dan menjalankan Apache Spark mode Fully Distributed akan jauh lebih mudah dan murah jika menggunakan cloud services seperti halnya Amazon Web Services (AWS) dibandingkan dengan menjalankannya di rumah sendiri (akan membutuhkan paling tidak 3 komputer, Local Area Network, dan install Apache Spark di tiap komputer tersebut).
 |
| Ilustrasi : ambsoft.de |
Apa yang perlu disiapkan?
#1 Install Apache Spark mode Standalone di local environment
Bisa menggunakan laptop Windows, MacOS, ataupun Linux.
Bagi pengguna MacOS, silakan ikuti tutorialnya disini : Cara Install dan Menjalankan Apache Spark pada MacOS Catalina
Untuk pengguna Windows 10 atau 7, tutorialnya ada disini: Membuat dan Menjalankan Aplikasi Apache Spark dengan Intellij IDEA pada OS Windows
#2 Gunakan Maven untuk mem-package program aplikasi Apache Spark
Jika Anda telah mengikuti tutorial untuk menginstal dan menjalankan Apache Spark baik di OS Windows ataupun MacOS seperti pada item #1, pasti sudah tahu bagaimana membuat program aplikasi berbasis Apache Spark dengan Maven.
Setelah program tersebut berhasil dibuat dan sudah dipastikan dapat berjalan normal, silakan package program aplikasi tersebut dalam bentuk file Jar.
Caranya: klik panel Maven pada bagian ujung kanan IDE (disini kita menggunakan Intellij IDEA), kemudian klik execute maven goal ( logo m ), kemudian execute command : "mvn clean package".
 |
execute maven goal: mvn clean package
|
Hasilnya, program Java aplikasi Apache Spark akan di-package ke dalam bentuk file Jar.
File Jar ini secara otomatis akan disimpan di directory 'target' (sub directory dari Maven Project Directory).
Pada tutorial ini, file Jar tersebut diubah nama menjadi 'spark-wordcount-1.0.jar'
 |
spark-wordcount-1.0.jar di Maven 'target' directory
|
#3 Upload file Jar program aplikasi Apache Spark ke Amazon S3 (Simple Storage Service)
Untuk bisa mengunakan layanan Amazon S3 (Simple Storage Service) dan Amazon Elastic MapReduce (Amazon EMR), kita mesti punya akun Amazon Web Services (AWS).
Kita bisa register secara gratis di https://aws.amazon.com/
Setelah berhasil memiliki akun AWS, login ke Amazon S3 dan buat bucket untuk menyimpan file Jar program aplikasi Apache Spark yang akan dijalankan (spark-wordcount-1.0.jar), file input yang hendak diproses, dan file-file output.
Membuat bucket di Amazon S3 sangatlah mudah: klik button 'Create bucket', kemudian akan tampil dialog box.
Ketik nama bucket yang dikehendaki, pilih region, kemudian klik 'create'.
Pada tutorial ini digunakan nama 'tekbig-spark'.
Setelah itu, buat dua folder di dalam bucket 'tekbig-spark', yaitu: folder apps dan input.
Caranya tidak sulit: klik bucket 'tekbig-spark', kemudian klik button 'Create folder'.
 |
Folder apps dan input pada bucket tekbig-spark
|
Upload file 'spark-wordcount-1.0.jar' ke folder apps dan file 'silicon-valley.txt' ke folder input.
Membuat Kluster di Amazon Elastic MapReduce (Amazon EMR) untuk menjalankan Apache Spark
Untuk membuat Kluster di Amazon EMR (Elastic MapReduce), silakan login ke Console Amazon EMR.
Setelah berhasil login, kemudian silakan ikuti langkah-langkah berikut:
#1 Pada laman Amazon EMR klik button 'Create cluster', lalu klik 'Go to advanced options'
 |
Create cluster
|
#2 Lakukan pengaturan pada 'Software Configuration' (untuk keperluan ini kita cukup install Hadoop dan Spark)
 |
Cukup install Hadoop dan Spark
|
#3 Pada paragraf 'Steps (optional), pilih 'Spark application' pada drop down menu 'Step type', lalu klik 'Add step'
 |
Step type : Spark application
|
#4 Setelah klik 'Add step' akan muncul dialog box berikut :
 |
Spark application options dan arguments
|
Isi kolom 'Name' dengan 'Spark Application' (atau gunakan nama lain sesuai selera).
Pada kolom 'Deploy mode' pilih 'Cluster'.
Isi kolom 'Spark-submit options' dengan nama class pada 'spark-wordcount-1.0.jar' yang memuat fungsi 'main' (disini kita isi --class com.teknologibigdata.spark.WordCount karena fungsi 'main' dari 'spark-wordcount-1.0.jar' ada pada class 'WordCount.java' yang berada dalam Java package 'com.teknologibigdata.spark').
Pada kolom Application location, isi URI dari 'spark-wordcount-1.0.jar' yang telah di-upload ke Amazon S3 pada bucket 'tekbig-spark' folder 'apps'.
Argument diisi dengan:
1. URI file input yang hendak diproses (silicon-valley.txt) yang telah di-upload ke bucket 'tekbig-spark' folder 'input'.
2. URI dari folder yang akan digunakan untuk menyimpan file-file hasil pemrosesan oleh Spark (disini folder tersebut diberi nama 'output' yang dibuat di dalam bucket 'tekbig-spark').
Catatan: folder 'output' ini akan dibuat secara otomatis dan tidak boleh dibuat secara manual seperti halnya membuat folder 'apps' dan 'input'.
Terakhir, pada kolom 'Action on failure' kita pilih 'Terminate cluster', lalu klik button 'Add'.
Sebagai hasilnya adalah seperti pada gambar berikut, kemudian klik 'Next'
 |
Step dengan type 'Spark application' telah berhasil dibuat
|
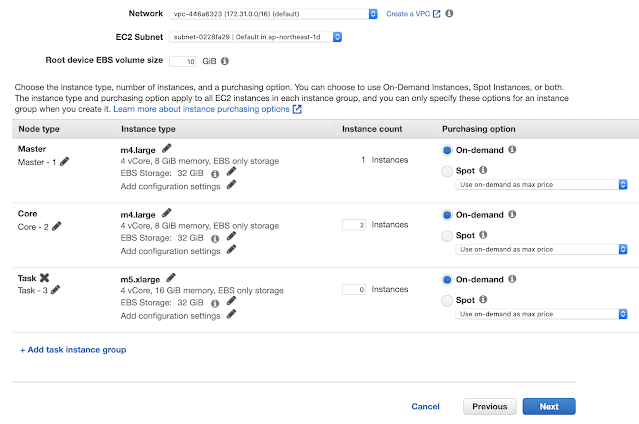
#5 Hardware Configuration
Setelah berhasil membuat Step dengan type Spark application, tahap selanjutnya adalah Hardware Configuration.
Disini kita hanya menggunakan 1 Master node dan 2 Core node, masing-masing dipilih type m4.large (4 vCore, 8 GiB RAM, 32 GiB Storage).
Bila ingin menggunakan type lain, bisa diubah dengan mengklik simbol 'pensil'.

 |
Hardware Configuration
|
Selesai Hardware Configuration, silakan klik 'Next'.
#6 Edit General Cluster Settings
Pada paragraf 'General Options', isi field 'Cluster name' dengan nama yang dikehendaki (disini saya beri nama 'TekbigSparkCluster').
Kemudian, tentukan folder di Amazon S3 sebagai tempat penyimpanan 'Logging'.

Selanjutnya klik 'Next'
#7 Security Options

Pada field 'EC2 key pair' saya isi 'SSH From My MacBook Pro 2017' karena saya telah membuat EC2 key pair untuk keperluan Interactive Login via SSH ke Master node kluster Amazon EMR.
Jika anda ingin membuat EC2 key pair juga, silakan ikuti tutorial ini : Cara Koneksi ke Kluster Elastic MapReduce (EMR) Menggunakan Secure Shell (SSH) dari Linux dan MacOS
Jika anda tidak memerlukan Interactive Login ke Master node EMR, tidak membuat EC2 key pair juga tidak masalah.
Jadi, pada field 'EC2 key pair' pilih 'Proceed without an EC2 key pair'.
Kemudian, pada paragraf 'Permissions' cukup biarkan 'Default' saja, lalu klik 'Create Cluster'
#8 Cluster Starting, Running, Waiting --> Terminate
Pada tahap ini, kluster Amazon EMR akan dijalankan secara otomatis dengan urutan Starting (mulai di-start) -> Running (menjalankan program aplikasi Spark dan memproses file input, yang dua-duanya telah kita upload ke Amazon S3) -> Waiting (telah selesai menjalankan program aplikasi Spark tersebut).
Jika kluster EMR sudah pada status Waiting, berarti semua proses sudah selesai, dan sudah saatnya kluster harus dimatikan (di-Terminate) dengan mengklik button 'Terminate'.
Catatan : jika kluster EMR tidak di-Terminate, maka kita akan terus dikenakan biaya sewa penggunaan yang dihitung per-jam.
 |
Starting
|
 |
Running
|
 |
Waiting after last step completed
|
 |
Terminate cluster
|
#9 Check Hasilnya di Amazon S3
Sekarang di bucket 'tekbig-spark' sudah ada folder 'output' (sebelumnya hanya ada folder 'apps' dan 'input').

Kita coba buka folder 'output', dan isinya adalah hasil processing file 'silicon-valley.txt' yang ada di folder 'input', oleh program 'spark-wordcount-1.0.jar' di folder 'apps'.

Disini kita coba buka file 'part-00006...' dan file 'part-00007...':


Demikian, kita telah berhasil menjalankan program Wordcount berbasis Apache Spark pada kluster Hadoop fully distributed dengan menggunakan layanan Amazon Elastic MapReduce (EMR).
Setelah saya cek billing, biaya yang dikenakan tidak lebih dari USD 0.1 ( Jika kurs USD 1 = IDR 15.000, maka biaya penggunaan Amazon EMR pada tutorial ini tidak lebih dari Rp 1.500,- ).
Murah sekali bukan!?









Comments
https://www.procoscare.com
Eyeliner services In Hyderabad
permanent eyeliner services in Hyderabad